Agentic AI is redefining the infrastructure standards that we just got used to. For the better part of a decade, the Microservice has been the undisputed unit of value. We spent years perfecting the art of the stateless, predictable container, wrapping it in layers of GitOps and CI/CD pipelines to ensure that what we deployed yesterday is exactly what runs tomorrow. And of course, everything must be “YAML”-filed.
While rarely seen yet in the wild, a new occupant will appear in our clusters: the Autonomous Agent.
Thanks for reading Zeitgeist of Bytes! Subscribe for free to receive new posts and support my work.
I think we have the right engine, but we are using the wrong blueprints. Kubernetes remains the only platform capable of hosting the agentic future, but the design patterns we’ve inherited, the “best practices” of 2020, are actively hindering the growth of autonomous systems. To serve an agentic ecosystem, we must stop treating agents like static web apps and start treating them like the dynamic, cognitive processes they are.
This post is the extended version of my recently at the Agentic AI Foundation published blog: https://aaif.io/blog/agentic-ai-infrastructure-on-kubernetes/
The Problem with Predictability
The core of the conflict lies in the nature of the workload. Traditional Kubernetes patterns are religious about “Desired State.” A human defines exactly how many replicas should run, how many it must be at least, how many it can be at max and what their limits are.
Agents, by contrast, are inherently non-deterministic. They don’t just respond to traffic; they generate logic, spawn sub-tasks, and mutate their own requirements based on the complexity of the goal at hand. (Keep this thought for a moment in you rhead, we will need it later).
Look at a tool like Goose. When Goose is tasked with a migration, it autonomously decides which tools to invoke. If it needs a temporary Python environment to process a dataset, it creates one. Our current GitOps flow, requiring a human-vetted PR for every infrastructure change, is a brick wall in these cases.
Our current infrastructure treats a “crash” as a failure. But an agent might purposely spin up a temporary environment to test a hypothesis and then tear it all down. This “intentional instability” looks like a failure to a traditional orchestrator, but it is actually the heartbeat of autonomous reasoning.
Thanks for reading Zeitgeist of Bytes! Subscribe for free to receive new posts and support my work.
Building the Four Pillars of the Agentic Runtime
And why there might be much more than that.
I initially wrote “To bridge this gap”, but I think that’s wrong. It’s new requirements, not a wrong development. Companies are looking for stability, not chaos. But Agentic means chaos, for the good and for the bad.
1. Safety through Isolation and Sandboxing
When an agent writes and executes its own code, standard Docker containers (sharing a host kernel) are a liability. They can become a risk in themselves, intended and unintended.
We have to consider at least things like Kata Containers or gVisor as a default and ensure by policies that there is no other way. Google identified this risk early and donated a project called Agent Sandbox to the Kubernetes SIGs for further development.
That requires an isolation for every tool call. If an agent “hallucinates” a destructive script, it occurs in a throwaway environment that vanishes in milliseconds.
2. Stateful Memory Fabrics aka a Cognitive Storage Class
We are moving past the “stateless sin” of early AI. The state, memory, context, indexes, and structure all require persistence, which is fast and efficient but lasts longer than any chat.
Agents required an integrated, tiered Cognitive Memory layer directly into the Kubernetes storage class. This moves from local KV-caches for active reasoning to shared memory for agent swarms (via protocols like MCP), and finally to vector-native storage for long-term “experience.” Besides, classic object storage is in high demand.
One of my thoughts would be the memory sidecar. Instead of every time telling the agent what, how, and where to connect, have a sidecar that deploys alongside the agent and handles memory connections. This way, access management for certain data could also be managed.
Think I’m going to vibecode something :D
3. Dynamic and Fractional GPU Scheduling
We are entering the age of “Bursty Reasoning.” An agent might sit idle while waiting for an API request, then suddenly require a massive burst of compute to plan its next moves. Or you have OpenClaw running…Then it is more like drum fire…
Anyhow, static GPU reservation is an economic disaster. We need fractional vGPU scheduling and spatial multitasking, where the scheduler slices compute power in real-time based on the “importance” of a reasoning task.
We see here a lot of development, especially in the training and fine-tuning context, and the same methods are partially used also for inference. But I think in the future companies will have dozens, if not hundreds, of differently sized models with different requirements. This going to be a challenge to optimize.
4. Observability as Trust
An HTTP 200 status code no longer equals success.
When your monitoring tells you a request completed without error, but the agent’s underlying reasoning was incoherent or simply wrong, you have a false sense of security that is more dangerous than an outright failure. Traditional observability was built for deterministic systems: did the CPU spike, did the endpoint respond? These metrics remain necessary, but for agentic systems they are profoundly insufficient.
The shift is from system logs to reasoning traces. The natural extension point is OpenTelemetry, already deeply embedded across modern stacks, it’s the right foundation to build on rather than replace. What changes is the span payload. Alongside execution telemetry, we need to capture the chain of thought: intermediate reasoning steps, tool-call justifications, decision branches considered and rejected.
But what a challenge it is, please? LLMs don’t emit structured reasoning by default, and a verbose trace from a complex multi-step agent can easily overwhelm conventional trace storage. Sampling strategies and semantic compression will become part of the observability conversation in ways they weren’t before.
5.th? Policy as Reasoning (The Guardrail Layer)
In a world where agents spawn their own infrastructure, we can no longer rely on static RBAC.
The traditional access control model assumes a stable population of known actors requesting a bounded set of known operations. Agentic systems break this not because they are adversarial, but because they are generative. An agent operating autonomously can formulate infrastructure changes no human anticipated at policy-writing time. Static rules cannot cover a dynamic action space.
The shift is toward intent-based governance. The question is no longer just “is this principal authorized?” but “does this action align with what this agent was actually sent here to do?” That requires semantic reasoning to answer which is where the LLM-as-a-Judge sidecar comes in. A lightweight inference process intercepts proposed actions before execution, receiving the agent’s declared mission, its budget, and the proposed action itself, then produces a reasoned verdict on alignment. Only if the verdict is affirmative does the API call proceed.
Time for an Intent-based access control: IBAC.
The companies that treat this as an afterthought will find themselves exposed in ways that are hard to recover from. Intent-based governance needs to be designed into the runtime from the start, because the agents it governs are already reasoning about what they’re allowed to do.
Because of all of these challenges, we need, maybe, finally, Kubernetes v2. A chaos empwoering, secure environment for agents to go wild, without burning a company.
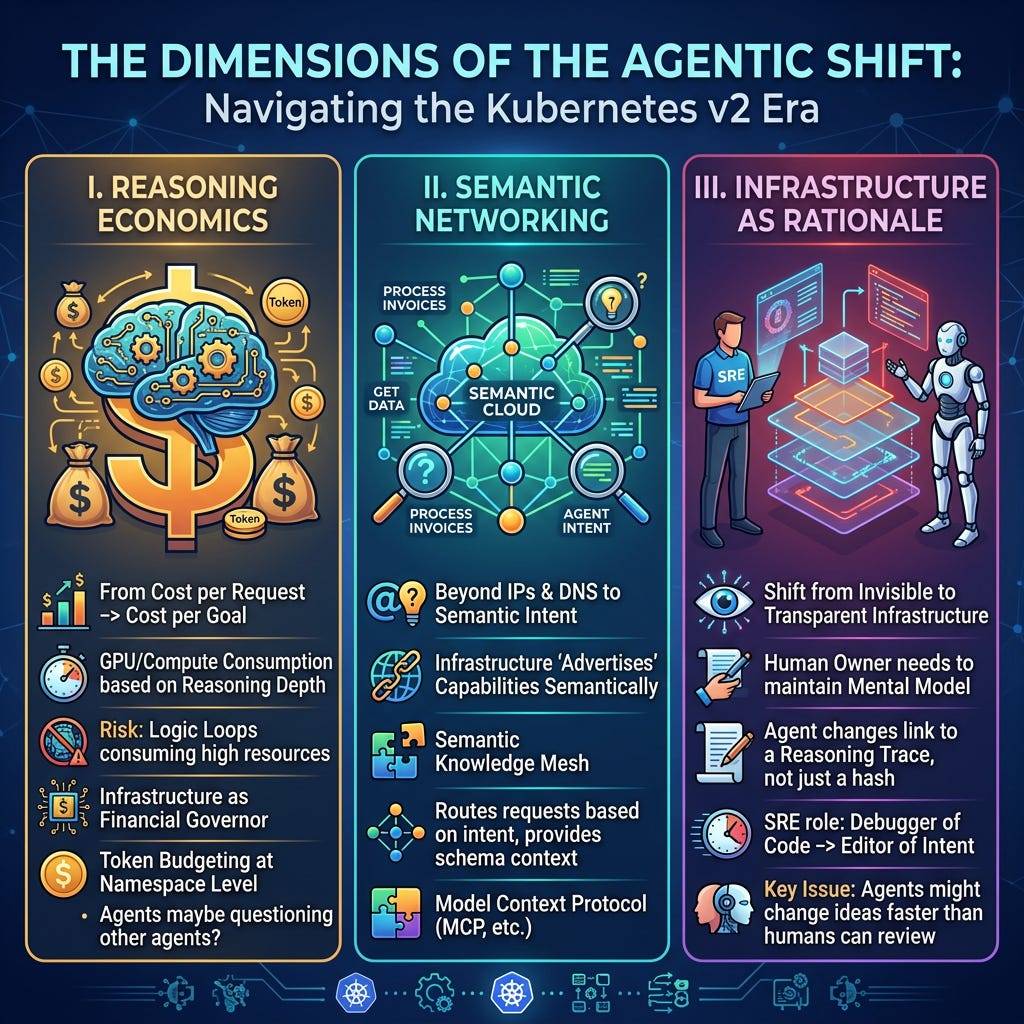
The Dimensions of the Agentic Shift
To truly understand the “Kubernetes v2” era, we have to look beyond the code and into the economics, the network and the human element.
I. Reasoning Economics
In the microservices era, costs were tied to traffic. In the agentic era, cost is tied to Reasoning Depth. An agent might get stuck in a logic loop, consuming $50 of GPU time to solve a $0.05 problem.
We need new patterns. For example, Infrastructure must act as a financial governor, providing Token Budgeting at the namespace level. We are moving from monitoring Cost per Request to Cost per Goal. This might require (not an infrastructure problem though), to have agents maybe questioning what other agents are doing. But especially with agents with autonomous freedome this will become highly relevant.
II. Semantic Networking
Standard networking is built on IPs and DNS. But agents don’t care about “Service A”; they care about “the service that can process a 2024 invoice.”
We need new patterns. Likea Semantic Knowledge Mesh. Using the Model Context Protocol (MCP, as long as it exists), the infrastructure “advertises” its capabilities semantically. The network routes agent requests based on intent and provides the necessary schema context automatically.
III. Infrastructure as Rationale
For the last decade, the goal of SRE was “invisible infrastructure.” For agents, invisibility is dangerous. If an agent changes a cluster config, the human “owner” loses the mental model of the system.
We need new patterns. Think of it like a transparent introspection. When an agent modifies a manifest, the “commit message” isn’t a hash, it’s a link to a reasoning trace. The SRE’s role shifts from “debugger of code” to “editor of intent.” The key issue will be that agents might change their ideas and implementations more often than humans can answer…
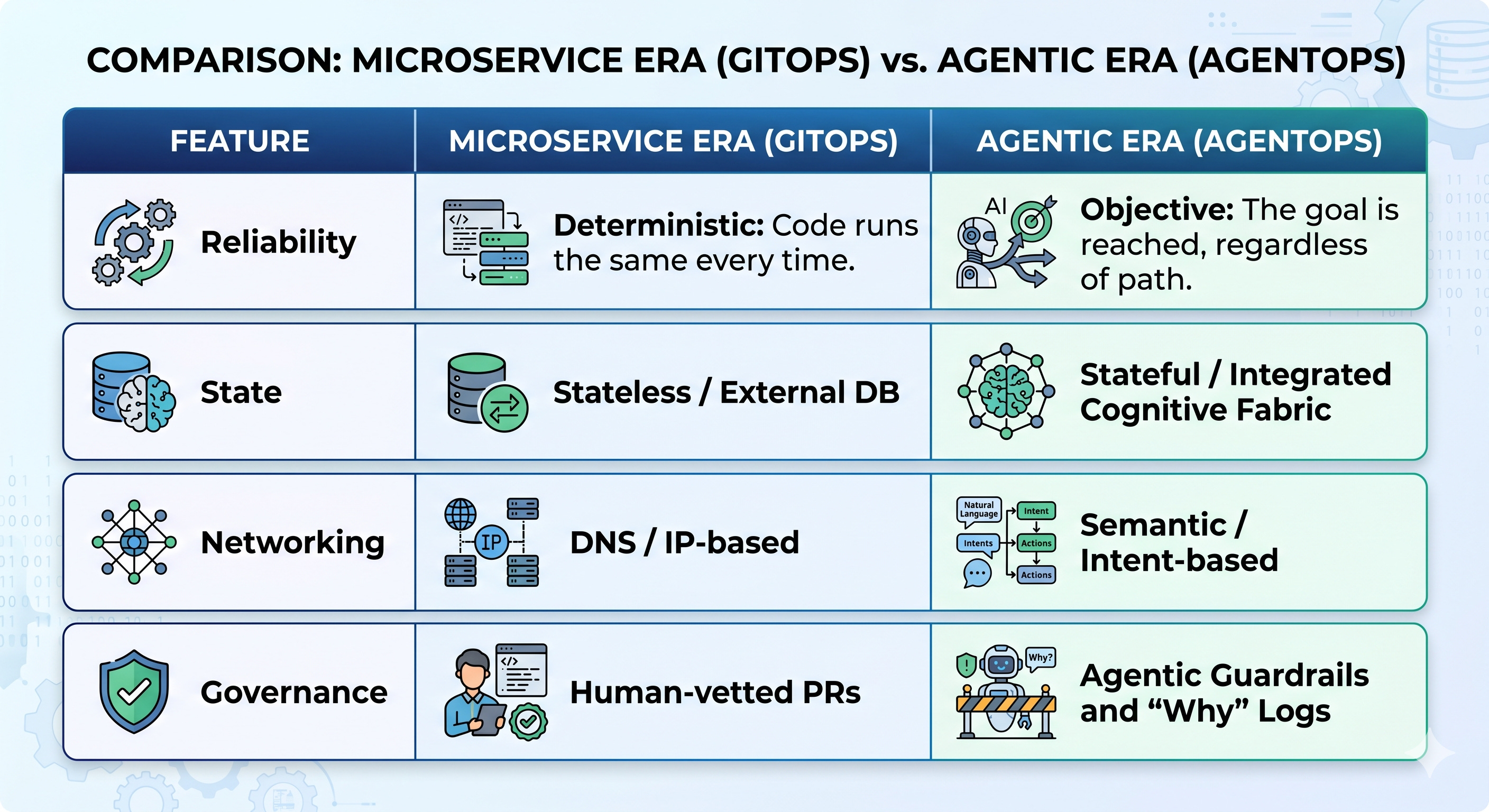
From GitOps to AgentOps: The New Kernel
We are moving away from static manifests toward the Agentic CRD (Custom Resource Definition). This doesn’t just define an image; it defines a goal, a budget, and a set of tool permissions.
The “Somehow” Era
For the last decade, a whole industry followed the mantra of: “It must run exactly the same on every machine.” In the agentic era, that shifts to: “It will somehow work on every machine.”
Does that feel scary? Yes! Do I think we are ready for it? No!
But if we don’t solve the issue of unpredictability and raise standards in quality of agentic-generated conditions, we will hit some brutal years.
By embracing this “somehow,” we gain immense power and speed. But we also surrender the comfort of the “frozen” production environment. We are trading the safety of the “known state” for the efficiency of autonomous reasoning.
Kubernetes has won the battle to be the platform. Now, it is time to build the brain.